* 딥러닝 session은 Sung Kim님의 강의 (유튜브)를 요약/정리한 내용입니다.
** Sung Kim님의 강의와 자료는 아래의 자료를 참고하고 있습니다.
- Andrew Ng's ML class
- Convolutional Neural Networks for Visual Recognition
- Tensorflow
목표
기초적인 머신러닝 알고리즘의 이해
- Linear regression, Logistic regression(classification)
- Neural networks, Convolutional Neural Network, Recurrent Neural Network
01. Machine Learning Basics
머신러닝이란?
머신러닝은 사람이 모든 규칙을 만들어낼 수 없다는 한계를 극복하기 위해 나온 방법이다. 머신러닝은 말 그대로 기계가 학습한다는 뜻에서 컴퓨터가 인간의 도움이 없이 스스로 학습할 수 있는 것을 만들어내는 분야이다.
머신러닝의 두 가지 방식
Supervised learning(지도 학습)
정답이 있는 데이터 셋으로 학습하는 것
예시: 고양이, 개, 머그컵, 모자 등의 사진을 통해 학습시킨 뒤 사진을 보여주고 어떤 사진인지 예측하는 것
Unsupervised learning(비지도 학습)
정답이 없는 데이터셋이 있는 것
예시: 워드 클라우드, 구글 뉴스 그룹화
Supervised learning(지도 학습)의 유형
Regression
시간에 따라 시험 점수를 예측하는 것
Binary classification
시간에 따라 Pass/non-pass를 분류하는 것
Multi-label classification
시간에 따라 시험 점수(A, B, C, D, F)를 분류하는 것
02. Linear Regression
Linear Regression 방식
1. 데이터와 그래프를 보고 Linear regression 모델에 적합할지 가설을 세운다.

2. H(x) 가설에 데이터를 잘 나타낼 수 있는 W(weight), b(bias) 값을 찾는다.

3. 데이터를 잘 나타낼 수 있는 값 찾는 과정인 Cost function을 최소화하는 과정을 진행한다.
Cost fuction(Loss function)이란?

: 예측한 값이 실제 값과 얼마큼 차이를 보이는지 확인하는 함수
03. How to minimize cost
Cost(=Loss) 함수의 그래프
일차 함수인 H(xi)의 제곱을 취했을 때 cost함수는 아래와 같은 이차 함수 형태의 모형이 된다.

경사 하강법이란?
함수의 기울기를 구하고 경사의 절댓값이 낮은 쪽으로 이동시켜 극값에 이를 때까지 반복시키는 것이다. (출처: 경사 하강법 wikipedia)
학습을 하는 것은 cost를 최소화하는 값을 찾아가는 과정이다. cost function을 최소화하는데 사용하는 알고리즘은 Grdient descent algorithm(경사 하강법)이다.
경사 하강법의 방법
1. H(x)의 Weight과 b를 찾아서 실제 값과 예측값의 차이인 cost를 찾는다.
2. 파라미터(W, b)는 변경해가면서 cost를 최소화하는 값으로 선정한다.
04. Multivariable Linear Regression
Linear regression을 설계하기 위해 필요한 것
- Hypothesis 식
- Cost function
- Gradient descent algorithm
Multivariable linear regression(다항 선형 회귀)이란?
하나의 변수로 하나의 값을 예측하는 것이 선형 회귀라면 여러 개의 변수로 하나의 값을 예측하는 것이다. 간단한 예시로 수학(X1), 영어(X2), 국어(X3)의 중간고사 점수로 기말고사의 점수(Y)를 예측하는 것이라고 할 수 있다.
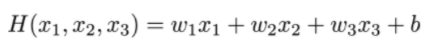

매개변수(W, b)가 많아지는 것을 처리하는 방법 = Matrix 사용
가로로는 한 ID를 나타내는 것이고 세로는 하나의 변수를 나타내는 것이다. 예를 들어 5명의 학생의 3가지 중간고사 과목 점수를 나타낼 때 x11, x12, x13은 영희의 중간고사 국어, 수학, 영어 점수를 나타내는 것이다.
H(가설) = XW

'A PIECE OF DATA > 🍕 딥러닝' 카테고리의 다른 글
| [딥러닝 기초] 머신러닝 기초④(ReLU, Vanishing gradient, dropout, ensemble) (0) | 2021.09.07 |
|---|---|
| [딥러닝 기초] 머신러닝 기초③(Neural Nets for XOR) (0) | 2021.09.03 |
| [딥러닝 기초] 머신러닝 기초②(logistic regression, Multinomial classification, learning rate (0) | 2021.08.27 |


